

Fleet maintenance operations have gotten weird over the past three years. You've got sensors throwing data at prediction models, algorithms flagging potential failures, and mechanics who still trust their gut over whatever the computer says. The disconnect between what the model predicts and what actually breaks down has become its own operational headache.
The real problem isn't whether predictive maintenance works—it absolutely can. The mess happens in the space between model output and actual work order creation. That's where most fleet operations fall apart, and where the difference between theoretical ROI and actual cost savings lives.
The telemetry-to-work-order pipeline nobody talks about
Most fleet managers think predictive maintenance stops at "model predicts failure." But you're dealing with a multi-stage pipeline that breaks constantly. Your telematics data flows through quality checks, gets processed by models, triggers alerts, requires validation, and eventually—maybe—becomes an actual work order that a real mechanic executes.
Vehicle sensors generate about 400-500 data points per vehicle per day in a mid-sized delivery fleet operation. Maybe 60% of that data arrives clean enough to use. Your model runs predictions every 4-6 hours, generating roughly 20-30 alerts per day across a 100-vehicle fleet. Of those alerts, your maintenance team investigates maybe half. Of those investigated, perhaps 3-4 become actual preventive work orders.
The gaps in this pipeline cost more than the models save. A regional logistics company discovered their predictive maintenance system was generating $180k in annual savings on paper, but the operational overhead of managing false positives, missed alerts, and coordination failures was eating $210k in labor costs. They were literally paying to make their maintenance operation worse.
Data quality becomes the silent killer here. Your ECM throws error codes that mean nothing. GPS data arrives 3 hours late. Temperature sensors fail in exactly the conditions you need them most. One bad sensor cascade—like when a faulty alternator causes voltage irregularities across multiple systems—can poison an entire day's worth of predictions.
Quick sketch of the telemetry-to-work-order flow:
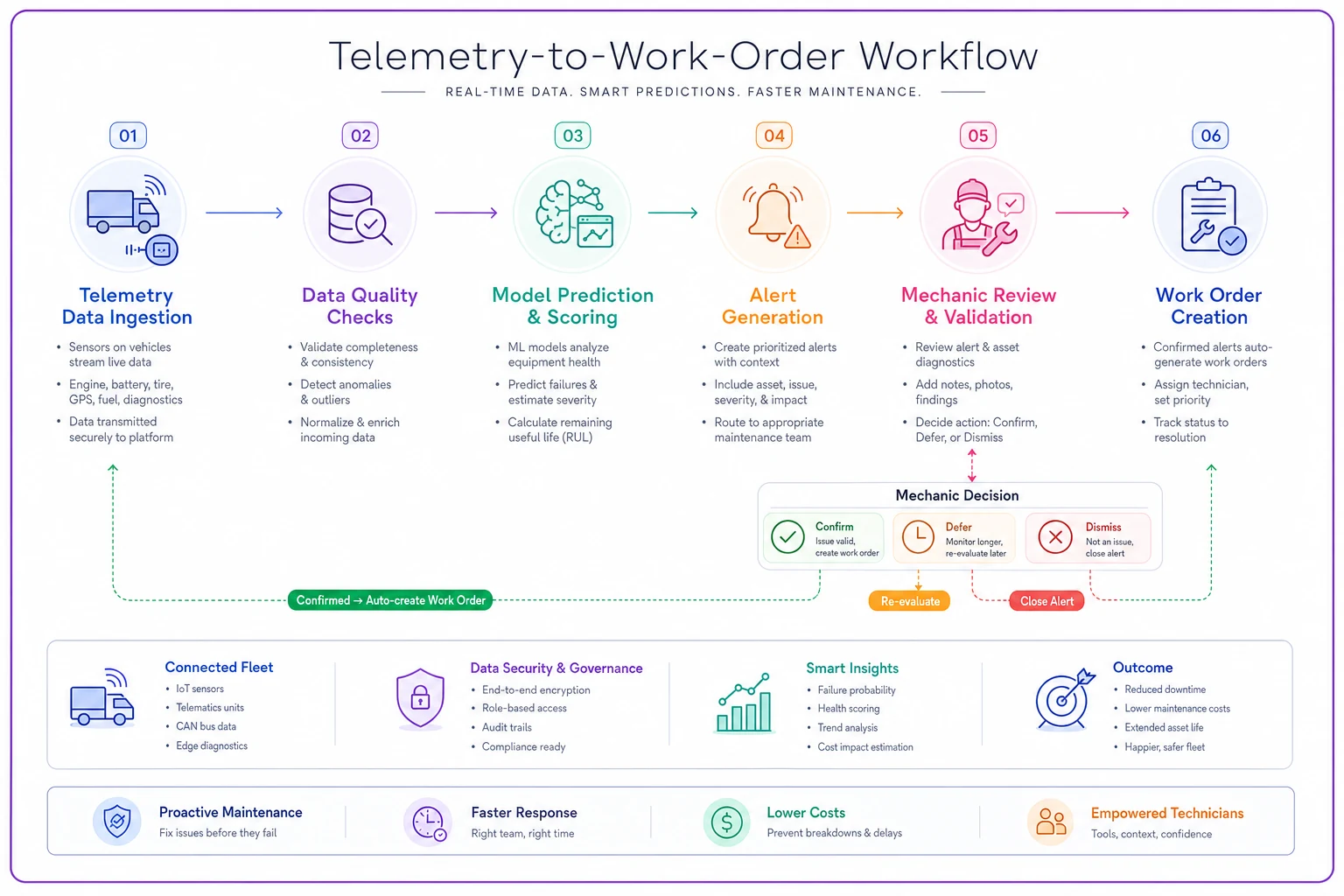
Even with the diagram, the point remains: the pipeline is fragile at many handoffs. If any stage drops data, delays processing, or misroutes alerts, the whole system produces noise instead of value.
Feature stability monitoring that actually matters
The features your model relies on drift constantly, but not in the academic way data scientists worry about. Real drift looks like this: your model trained on vehicles that averaged 180 miles per day suddenly sees a fleet averaging 310 miles daily because you landed a new contract. Or maintenance schedules shift from 5-day cycles to 7-day cycles because you lost two mechanics.
Prevent costly breakdowns with proactive maintenance.
Fleetelyly helps you schedule, track, and manage every vehicle service efficiently.
- Automated maintenance reminders
- Real-time service tracking
- Parts inventory integration
No credit card required
Traditional MLOps talks about statistical drift detection—KL divergence, PSI scores, whatever. But operational drift kills you first. When your fleet starts using different oil viscosity because purchasing found a bulk deal, your oil pressure predictions go haywire. When drivers start taking different routes to avoid new toll roads, your wear patterns change completely.
-
Average daily mileage per vehicle class
-
Maintenance interval consistency
-
Parts supplier changes
-
Route pattern shifts
-
Driver rotation frequency
A waste management fleet noticed their brake pad predictions failing catastrophically. The model showed 89% accuracy in testing but dropped to 41% in production. They'd switched from residential to commercial routes, doubling the average vehicle weight. The model features looked statistically stable—same value ranges, similar distributions—but operationally everything had changed.
You need two monitoring systems: one for mathematical drift (the stuff your data team cares about) and one for operational drift (the stuff that actually breaks your predictions). Most teams only build the first one.
Retraining cadence versus operational reality
Every ML textbook says retrain your models regularly. In fleet maintenance, "regularly" means something different depending on what breaks and when. Engine failure models might stay stable for 8-12 months. Tire wear models need updates every 6-8 weeks during season changes. Brake system models fluctuate with route assignments.
The standard approach—retrain everything monthly—wastes computational resources and introduces unnecessary instability. A municipal fleet operation found that aggressive retraining actually decreased their prediction accuracy. Their monthly retrained models kept flip-flopping on long-term degradation patterns, essentially forgetting what they'd learned about gradual component wear.
Tie retraining to operational triggers, not calendar dates. Retrain when:
-
You onboard vehicles with different specifications
-
Maintenance procedures change significantly
-
You switch parts suppliers or fluid types
-
Route patterns shift by more than 20%
-
Seasonal transitions occur (summer/winter driving conditions)
One trucking company built "retraining rules"—specific operational conditions that triggered model updates. New vehicle type added to fleet? Retrain the relevant subsystem models. Switch from synthetic to conventional oil? Retrain engine wear models. This cut their retraining compute costs by 60% while improving prediction accuracy.
The retraining pipeline itself needs operational consideration. You can't just swap models mid-day when mechanics are processing work orders. You need staged rollouts, A/B testing in production, and rollback procedures when the new model starts hallucinating failures.
Alert validation workflows and the trust problem
Your mechanics don't trust your model. They've seen too many false alarms, missed too many actual failures the model didn't catch, and generally view the whole system as management's latest attempt to make their jobs harder.
The alert validation workflow becomes the bridge between model output and mechanic trust. But most operations build this backwards—they start with the assumption that the model is right and mechanics need to justify ignoring it. This creates an adversarial dynamic where mechanics feel micromanaged by an algorithm.
A distribution fleet flipped this around with what they called "mechanic-first validation." When the model generates an alert, it goes to the senior mechanic first, not management. The mechanic can:
-
Validate and create immediate work order
-
Flag for inspection within X days
-
Dismiss with documented reason
-
Request additional diagnostic data
Mechanics' dismissal reasons feed back into the model. "Dismissed - just replaced this component last week" indicates a data pipeline problem. "Dismissed - this error code always appears in cold weather" suggests a feature engineering issue. "Dismissed - checked and found no issue" might mean the detection threshold needs adjustment.
Pro-tip: Route initial alerts to senior mechanics to collect high-quality dismissal reasons that directly improve model thresholds and data pipelines.
This creates a positive feedback loop. Mechanics see their expertise improving the system. The model gets better with their input. Trust builds gradually. Within six months, the same mechanics who initially ignored every alert were actively requesting predictions for vehicles showing subtle symptoms.
The workflow needs structure though. You track:
-
Alert-to-investigation time
-
Investigation-to-decision time
-
False positive rate by mechanic
-
Model agreement rate over time
-
Dismissed alert patterns
Without this structure, you're just adding steps to your maintenance process without learning anything.
Human-in-the-loop work order generation
Assuming the model should automatically generate work orders is the biggest mistake in predictive maintenance model operations. This sounds efficient but creates chaos. Your model doesn't understand shop capacity, parts availability, route schedules, or customer commitments.
Human-in-the-loop workflows add a translation layer between prediction and action. But most operations implement this wrong—they just add an approval step where someone clicks "yes" or "no" on model recommendations. That's not human-in-the-loop; that's human-as-rubber-stamp.
Real human-in-the-loop means your maintenance coordinator sees:
-
Model prediction with confidence score
-
Historical accuracy for this specific prediction type
-
Current shop capacity and schedule
-
Parts availability and lead time
-
Vehicle's upcoming route commitments
-
Cost-benefit analysis of immediate vs. delayed maintenance
They then make nuanced decisions. Maybe the model predicts transmission failure in 200 miles with 78% confidence. But this vehicle is scheduled for routine service in 150 miles anyway. The coordinator bundles the work, saving a separate shop visit.
A food delivery fleet built this into their operation beautifully. Their maintenance planning software shows model predictions alongside operational context. The system suggests optimal work order timing based on routes, shop capacity, and parts availability. But humans make the final call, often spotting patterns the model misses.
Their coordinator noticed the model kept predicting starter motor failures on vehicles parked near the loading dock. Turns out, the loading dock's industrial magnets were interfering with sensor readings. No amount of model training would have caught this—it required human understanding of the physical environment.
Common pitfalls that kill predictive maintenance operations
The failures follow patterns. First: treating all predictions equally. Your model might predict 15 different failure types, but operationally, they're not equivalent. Predicting brake failure matters more than predicting wiper blade degradation. Yet most systems treat every alert with the same urgency.
The second killer: ignoring the time component of predictions. Your model says "transmission failure likely." But likely when? Tomorrow? Next month? Next year? Without temporal precision, maintenance teams can't prioritize effectively. One fleet learned this after replacing 30 transmissions "preventively" that would have lasted another 40,000 miles.
Data lag destroys prediction value faster than anything else. Your model trains on data where sensor readings preceded failures by days or weeks. But in production, if your telemetry pipeline has a 72-hour delay, you're predicting the past. A shipping company discovered their "predictive" system was actually detecting failures 2 days after mechanics had already noticed symptoms.
The feedback loop problem compounds everything. Model makes prediction → mechanic investigates → finds nothing → no feedback to model → model keeps making same prediction → mechanic starts ignoring all predictions → actual failure occurs → trust erodes further. Breaking this cycle requires deliberate feedback mechanisms, not just hoping mechanics will document everything.
Then there's the "set and forget" mindset. Teams deploy predictive maintenance, see initial results, then stop monitoring model performance. Six months later, accuracy has degraded, but nobody notices because they're not tracking the right metrics.
Building the MLOps checklist for maintenance operations
Data Pipeline Health
-
Sensor data completeness (aim for >85% complete records)
-
Latency from reading to model input (<4 hours for critical systems)
-
Data quality scores by vehicle and sensor type
-
Failed transmission alerts and recovery time
Model Performance Metrics
-
Precision/recall by failure type, not aggregate
-
Time-to-failure accuracy (predicted vs. actual)
-
False positive cost (unnecessary inspections)
-
False negative cost (missed failures leading to breakdowns)
| Category | Key items |
|---|---|
| Operational Integration | Alert-to-work-order conversion rate; Mechanic acceptance/rejection rates with reasons; Work order timing optimization (bundling success); Parts ordering lead time alignment |
| Feedback Mechanisms | Post-inspection result capture; Mechanic annotation system for predictions; Failure post-mortems feeding back to training data; Regular model vs. mechanic prediction comparisons |
| Retraining Triggers | Fleet composition changes; Operational pattern shifts (routes, schedules); Seasonal transitions; Maintenance procedure updates; Supplier or parts changes |
Operational Integration
-
Alert-to-work-order conversion rate
-
Mechanic acceptance/rejection rates with reasons
-
Work order timing optimization (bundling success)
-
Parts ordering lead time alignment
Feedback Mechanisms
-
Post-inspection result capture
-
Mechanic annotation system for predictions
-
Failure post-mortems feeding back to training data
-
Regular model vs. mechanic prediction comparisons
Retraining Triggers
-
Fleet composition changes
-
Operational pattern shifts (routes, schedules)
-
Seasonal transitions
-
Maintenance procedure updates
-
Supplier or parts changes
This isn't a complete list—your operation will have unique requirements. But without at least these elements, you're running predictive maintenance blind.
The reality check on ROI
Most predictive maintenance ROI calculations are fantasy. They assume perfect prediction accuracy, instant work order generation, and zero operational friction. Real ROI comes from three places:
First, catastrophic failure prevention. Not every failure—just the ones that strand vehicles, damage other components, or risk safety. One prevented engine seizure can justify months of false positives.
Second, maintenance scheduling optimization. Bundling predicted issues with scheduled maintenance, reducing vehicle downtime, and smoothing shop workload. This often saves more than the predictions themselves.
Third, parts inventory optimization. Knowing what's likely to fail helps you stock the right parts without overloading inventory. A parts manager said their predictive system's biggest value wasn't preventing failures—it was avoiding expedited shipping costs for emergency parts orders.
The anti-ROI comes from operational overhead, false positive investigations, mechanic time spent validating alerts, and the coordination cost of human-in-the-loop workflows. Most operations underestimate these costs by 50-70%.
Moving from chaos to systematic improvement
Getting predictive maintenance model operations right means accepting that it's not a technology problem—it's a systems problem. Your model might be highly accurate in testing, but if mechanics don't trust it, alerts arrive too late, or work orders pile up unexecuted, you're just burning money on compute costs.
Start with the basics: clean up your data pipeline, establish feedback loops, and build trust with your maintenance team. Add complexity gradually. Every new feature or model improvement should solve a specific operational problem, not just improve abstract metrics.
The teams that succeed treat predictive maintenance as an operational capability that happens to use ML, not an ML system bolted onto operations. They measure success by reduced breakdowns, optimized maintenance schedules, and mechanic satisfaction—not by model accuracy scores.
Most importantly, they recognize that human judgment still matters. The best predictive maintenance operation isn't one where models make all decisions. It's one where models and mechanics work together, each contributing their strengths. Models catch patterns humans miss. Humans understand context models can't grasp.
Your predictive maintenance system will never be perfect. But with the right operational framework, monitoring discipline, and human-in-the-loop workflows, it can be good enough to transform your maintenance operation from reactive firefighting to proactive management. That's when the real value emerges—not from the model's predictions, but from the operational excellence those predictions enable.
Ready to maximize fleet uptime and reduce maintenance costs?
Join 2,000+ fleet managers using Fleetelyly to streamline maintenance workflows and improve vehicle reliability.