

Your fleet throws 400+ diagnostic codes at you daily. P0171, P0420, U0100, B1234 — each one demanding attention. Some mean a truck breaks down tomorrow. Others mean nothing for 3,000 miles. Most fleet managers either overreact to everything or miss critical failures because they're drowning in noise.
The difference between a $200 scheduled repair and a $4,000 roadside breakdown often comes down to how quickly you categorize that initial fault code. Not whether you see it — modern telematics ensures you see everything — but whether you know what to do with it in the first 30 seconds.
The shops that keep trucks rolling don't have better mechanics or newer equipment. They have clear decision trees that turn fault codes into the right type of work order, automatically, every single time.
The Real Cost of Bad Triage Decisions
A distribution fleet in Ohio learned this expensively last year. Their Freightliner Cascadias started throwing DEF quality fault codes (P203F). The maintenance supervisor figured they had time — afterliters don't fail immediately, right? Three trucks derated on I-71 within 48 hours. Total cost: $14,000 in towing, emergency repairs, and missed deliveries.
Meanwhile, the same fleet was rushing trucks in for every ABS sensor code, creating 30+ unnecessary shop visits monthly. Each false alarm cost them roughly $400 in lost revenue plus mechanic overtime.
This happens because most telematics fault code triage systems dump everything into one bucket. Your dashboard shows 50 active faults across 30 vehicles. Which ones matter today? Which ones can wait until the next PM? Which ones just need monitoring?
Without clear decision rules, maintenance teams make gut calls. Sometimes they're right. Often they're expensive mistakes.
Building Decision Trees That Actually Work
Effective fault code triage starts with understanding that not all codes are created equal. A P0087 (fuel rail pressure too low) on a 2019 Cummins X15 requires completely different handling than the same code on a 2022 Detroit DD15.
Prevent costly breakdowns with proactive maintenance.
Fleetelyly helps you schedule, track, and manage every vehicle service efficiently.
- Automated maintenance reminders
- Real-time service tracking
- Parts inventory integration
No credit card required
Failure progression patterns matter more than the code name. Some faults deteriorate linearly — you have weeks to schedule repairs. Others hit a cliff. DEF system faults can go from warning to derate in hours. EGR valve codes might give you 2,000 miles.
Vehicle criticality layers change everything. A refrigerated trailer throwing a reefer unit fault during produce season gets immediate attention. The same fault in January on a backup unit? Schedule it for next week. Operational context matters more than the code itself.
Cost multiplication factors hide in plain sight. Certain codes cascade. An ignored NOx sensor fault becomes a DEF pump failure becomes a complete aftertreatment replacement. Your triage system needs to recognize these patterns and escalate accordingly.
The Three-Tier Triage Framework
The most successful fleets organize fault codes into three clear categories, each with specific triggers and workflows:
Immediate Response Codes
These codes trigger instant action — usually within 2-4 hours. They represent imminent breakdowns, safety issues, or regulatory violations.
Common immediate triggers:
-
Coolant temperature above 235°F (imminent engine damage)
-
Oil pressure below 15 PSI at idle
-
Critical DEF faults with active derates
-
Brake system pressure loss codes
-
Transmission slipping faults on active routes
Each immediate code needs a specific escalation path. A coolant temp spike on I-80 in Nevada requires different response than the same code in your yard.
Scheduled Maintenance Codes
These represent real issues that need attention but offer planning windows. Typically 3-30 days depending on severity and progression rate.
Typical scheduled triggers:
-
DPF regeneration frequency increasing (more than 3 per week)
-
EGR differential pressure out of range
-
Non-critical sensor faults
-
Minor oil leaks detected
-
Tire pressure variations beyond 10%
Setting clear windows based on deterioration curves is key. A partial EGR blockage might give you 3,000 safe miles. Your system schedules repair for the 2,000-mile mark, building in buffer for route variations.
Monitor-Only Codes
These codes get logged but don't trigger work orders unless patterns emerge or thresholds are exceeded.
Standard monitor triggers:
-
Intermittent communication faults that self-clear
-
Pending codes without confirmed faults
-
Known false positives for specific vehicle models
-
Seasonal codes (like cold-start issues in winter)
Monitoring doesn't mean ignoring. Your system tracks frequency, looks for escalation patterns, and converts to scheduled maintenance when thresholds are hit.
Creating Practical Decision Maps
Most fleets try to build perfect decision trees covering every possible scenario. Six months later, they have a 400-page document nobody uses.
Start with your top 20 most frequent codes. Map them completely before expanding. For each code, document the basic flow. When a code appears in your telematics system, check vehicle model and year against known patterns. Then evaluate operational context — location, load, route. Assign to the right triage category and create the appropriate work order with clear timing expectations.
Override conditions need documentation too. Previous repairs for the same code within 30 days change everything. Multiple vehicles showing identical codes suggest systemic issues. Codes appearing during specific operational conditions might be environmental, not mechanical.
Escalation triggers matter most. Code frequency exceeding threshold. Additional related codes appearing. Vehicle approaching critical maintenance windows.
Start with your top 20 most frequent codes.
The graphic shows the basic flow for each code: check vehicle, evaluate context, assign category, and create work order.
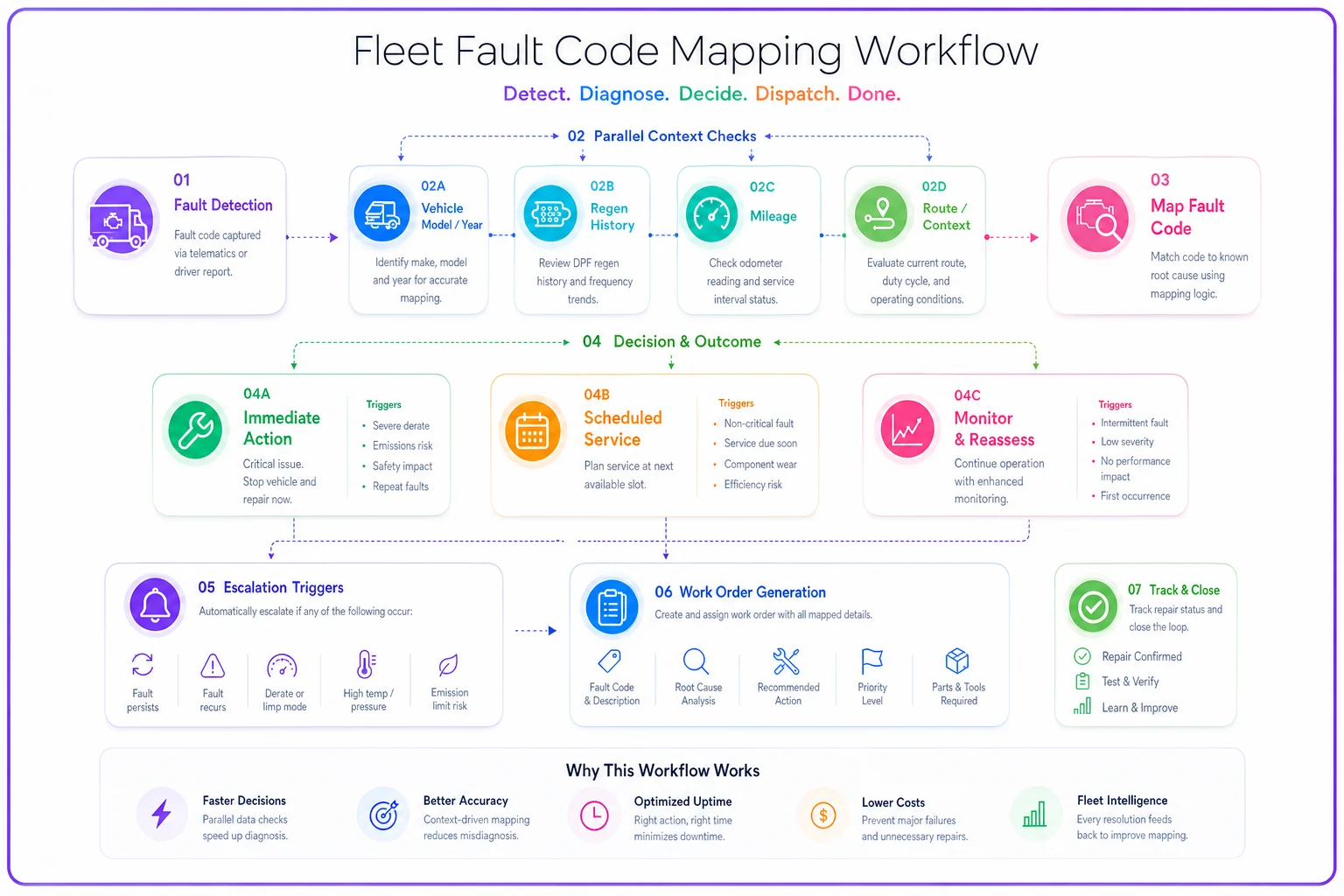
Escalation triggers matter most. Code frequency exceeding threshold. Additional related codes appearing. Vehicle approaching critical maintenance windows.
Real-World Mapping Examples
Scenario 1: DPF Pressure Differential (P2453)
Initial Detection:
2020 International LT throws P2453 during morning route
Decision Tree Path:
``
Fault Code P2453 Detected
├── Check Regeneration History
│ └── 5 regens in last 7 days (excessive)
├── Check Mileage Since Last DPF Service
│ └── 165,000 miles
├── Check Current Route
│ └── Local delivery, returns nightly
├── Check Fleet DPF Failure Data
│ └── Average progression to failure: 15 days
└── Triage Decision: Scheduled Maintenance (7-day window)
``
Work Order Generated: DPF inspection and potential cleaning, scheduled for weekend to avoid route disruption
Scenario 2: Oil Pressure Warning (P0521)
Initial Detection:
2018 Volvo VNL triggers low oil pressure during highway cruise
Decision considerations: Current pressure reading shows 8 PSI at 1400 RPM (critical). Oil level sensor reads normal range. Vehicle location: I-70, 45 miles from Denver shop. Load status: refrigerated pharmaceuticals.
Triage Result: Immediate response
Work Order Generated: Emergency dispatch to location, backup vehicle deployed, load transfer authorized
Scenario 3: ABS Sensor Intermittent (C0035)
Initial Detection:
2021 Kenworth T680 shows intermittent right rear ABS fault
The fault appeared twice in 30 days, both times self-clearing. No brake performance degradation detected. Both faults occurred during rain events. Vehicle PM due in 18 days.
Triage Result: Monitor only, flag for PM inspection
Work Order Generated: None immediate, added to PM checklist
SLA Windows and Automation Rules
Your triage categories mean nothing without enforceable timing rules and automated workflows. Each category needs specific windows and escalation paths.
Immediate Response SLAs
Response time: 15 minutes from code detection. Diagnosis window: 1 hour maximum. Repair decision: 2 hours maximum. Escalation every 30 minutes until resolved.
Immediate doesn't mean drop everything for every code. Your automation rules need intelligence. A coolant temp spike at 2 AM in your secured yard triggers a morning alert. The same spike at 2 PM on a highway triggers instant response.
Scheduled Maintenance SLAs
Initial review within 4 hours. Scheduling window based on severity tier:
| Severity Tier | Scheduling Window |
|---|---|
| Tier 1 | Within 72 hours |
| Tier 2 | Within 7 days |
| Tier 3 | Within 30 days or next PM |
Escalation triggers activate when code frequency doubles, related codes appear, or vehicle approaches tier deadline.
The automation here focuses on intelligent scheduling. Your system checks vehicle routes, shop capacity, and parts availability before setting appointments. A DEF pump code might have a 7-day window, but if that vehicle has a cross-country run on day 6, the system schedules for day 3.
Monitor-Only Thresholds
Weekly batch analysis reviews patterns. Escalation to scheduled maintenance happens when the same code appears 3 times in 30 days, multiple vehicles show identical codes, or codes correlate with performance degradation.
Auto-close conditions include no recurrence for 60 days, vehicle serviced for related system, or known false positive confirmed.
Common Decision Tree Failures
Even well-designed triage systems fail when they ignore operational reality.
Over-reliance on manufacturer severity creates problems. OEMs mark codes as critical based on worst-case scenarios. A "critical" emissions code might have zero impact on your local delivery routes but could shut down a long-haul truck. Your decision tree needs operational context, not just manufacturer ratings.
Ignoring fleet-specific patterns wastes resources. Your 2019 Mack Anthems might throw false EGR codes every winter. Your 2020 Peterbilts might have wonky speed sensors that self-correct. Building these patterns into your decision logic prevents unnecessary responses.
Static thresholds without learning miss optimization opportunities. A fixed "respond within 4 hours" rule for all critical codes ignores reality. Some codes deteriorate predictably — you can extend response windows based on historical progression data. Others are unpredictable — they need tighter windows regardless of past behavior.
Missing the cascade effect costs money. Individual codes seem manageable. Multiple related codes signal system failure. Your decision tree needs pattern recognition. Three minor exhaust codes together often predict DPF failure better than one critical code alone.
Implementing Automated Work Order Creation
The best decision tree means nothing if it requires manual work order creation. By the time someone reviews the code, checks the rules, and creates the ticket, your immediate response window is blown.
Modern telematics fault code triage systems need automated work order generation with intelligent routing.
Immediate response work orders get auto-generated with "CRITICAL" flags, routed to on-call supervisor phones, include vehicle location and load details, list nearest approved shops, pre-authorize emergency repair limits, and track response time from creation.
Scheduled maintenance work orders generate with appropriate priority levels, include fault history and progression data, check parts inventory before scheduling, route to appropriate shops based on expertise, and allow driver input on timing preferences.
Monitor-only tracking creates observation records, not work orders. Link related codes across vehicles. Generate pattern reports weekly. Convert to work orders when thresholds are hit. Archive after auto-close conditions are met.
The automation removes human delay while maintaining override capability. A supervisor can always upgrade a scheduled repair to immediate or downgrade a false alarm to monitor-only.
Building Your Implementation Roadmap
Most fleets try to implement complete fault code triage systems overnight. They fail. Start small, prove value, then expand.
Month 1: Foundation Map your top 10 most expensive fault codes. These usually account for 60% of your emergency repairs. Create simple decision trees for just these codes. Implement manual processes first — prove the logic works before automating.
Month 2-3: Automation basics Add automatic work order creation for your mapped codes. Start with scheduled maintenance categories — they're less risky than immediate response automation. Track metrics: response time, false positives, prevented breakdowns.
Month 4-6: Expansion Add 10 codes monthly. Refine timing windows based on actual data. Implement pattern recognition for multi-code scenarios. Add fleet-specific rules based on your breakdown history.
Month 7-12: Optimization Integrate with parts inventory systems. Add predictive elements based on vehicle age and mileage. Implement cost tracking to prove ROI. Expand to cover 80% of your common codes.
Measuring Success Beyond Breakdown Prevention
Effective fault code triage delivers measurable improvements across multiple metrics:
Direct cost reduction:
-
Fewer emergency repairs (30-40% reduction typical)
-
Lower towing costs (50% reduction achievable)
-
Reduced overtime labor (20-30% savings)
-
Better parts inventory management
Operational improvements:
-
Increased vehicle availability (5-8% improvement)
-
Higher on-time delivery rates
-
Reduced driver frustration with breakdowns
-
Better maintenance scheduling efficiency
Strategic advantages:
-
Proactive maintenance instead of reactive
-
Data-driven replacement decisions
-
Vendor performance tracking
-
Regulatory compliance documentation
Track these metrics monthly. A properly implemented triage system should show improvement within 90 days.
The Technology Stack Reality
Running fault code decision trees manually is like trying to direct air traffic with binoculars and a notepad. Possible, but unnecessarily risky. Modern operational platforms powered by AI automation handle the complexity while you focus on optimization.
The right platform integrates your telematics feed, applies your decision rules, generates work orders, and tracks outcomes automatically. It learns from patterns, adjusts thresholds based on results, and alerts you to emerging issues before they become fleet-wide problems.
This isn't about replacing human judgment — it's about freeing your team from repetitive triage tasks so they can focus on prevention and optimization. Your mechanics spend time fixing trucks, not sorting through fault codes. Your supervisors manage operations, not spreadsheets.
Telematics fault code triage isn't about perfection. It's about consistency. Every code gets evaluated the same way, every time. Your newest supervisor makes the same triage decision as your 20-year veteran. That consistency prevents both overreaction and dangerous neglect.
Start with your biggest pain points. Map the codes that cause the most downtime or cost the most money. Build simple decision trees. Test them manually. Then automate gradually.
Within six months, you'll wonder how you ever managed without clear triage rules. Your drivers trust that critical issues get immediate attention. Your maintenance team knows exactly what to prioritize. Your budget becomes predictable because emergency repairs become rare.
The fleets still drowning in diagnostic codes, making gut-call decisions face constant breakdowns while your trucks keep rolling. That's the real value of systematic fault code triage — it turns chaos into competitive advantage.
Ready to maximize fleet uptime and reduce maintenance costs?
Join 2,000+ fleet managers using Fleetelyly to streamline maintenance workflows and improve vehicle reliability.