

Every fleet manager knows the pattern. Monday morning, your telematics system dumps 247 alerts into the maintenance queue. Your team spends three hours sorting through them, finds maybe twelve that actually matter, and by Wednesday you're dealing with a roadside breakdown that somehow didn't trigger any alerts at all.
The problem isn't your telematics hardware. Modern sensors capture everything—engine codes, temperature spikes, pressure drops, acceleration patterns. The problem is that most fleets never properly tune their alert thresholds and filtering logic after initial setup. They accept default settings that generate mountains of false positives, or worse, they start ignoring alerts entirely because the signal-to-noise ratio makes them useless.
What makes this particularly frustrating is that buried in those 247 Monday alerts, there probably were early warning signs of that Wednesday breakdown. But when your team has to manually review every low-priority coolant temperature fluctuation and brief voltage dip, the patterns that actually predict failures become invisible.
The hidden costs of bad telematics alert tuning
Most fleets drastically underestimate what poor alert quality actually costs them. It's not just missed breakdowns or wasted technician hours.
Think about what happens in a typical 85-vehicle delivery fleet. Telematics throws an engine fault code on truck #42. The alert gets routed to maintenance, a technician pulls the vehicle, spends 45 minutes checking everything, finds nothing wrong, clears the code, releases the truck. Meanwhile, that route gets covered by overtime drivers or delayed deliveries. Same fault code triggers again two days later on three different trucks—same story, nothing actually wrong.
After a few weeks of this, your operations team starts second-guessing every maintenance pull request. Dispatchers push back when technicians want to inspect vehicles. Drivers stop reporting minor issues because "the sensors will catch it anyway." The maintenance team starts batching inspections to reduce disruptions, which means real issues sit longer before getting addressed.
Then there's alert fatigue on the technician side. When you're getting 40+ alerts per vehicle per week, mostly false positives, shortcuts develop fast. Quick visual checks replace thorough inspections. Pattern recognition replaces systematic diagnosis. You start assuming DTC P0171 is always just a loose gas cap because it has been the last eight times.
The worst part? Your telematics data becomes less valuable over time, not more. You're collecting millions of data points but your team trusts them less and less. When someone suggests updating alert thresholds, everyone rolls their eyes because "we tried that two years ago and it made things worse."
Why precision and recall targets actually matter
Most fleet operations miss something important about telematics alert tuning: you need different accuracy targets for different failure types. A catastrophic engine failure warning needs 95% recall even if that means accepting 60% precision. You'd rather inspect ten engines unnecessarily than miss one that's about to grenade. But a minor exhaust sensor fault? Maybe 80% precision with 70% recall is fine—you don't want your team chasing ghosts.
Prevent costly breakdowns with proactive maintenance.
Fleetelyly helps you schedule, track, and manage every vehicle service efficiently.
- Automated maintenance reminders
- Real-time service tracking
- Parts inventory integration
No credit card required
Telematics vendors rarely explain this tradeoff clearly. They'll promise "accurate fault detection" without specifying whether they're optimizing for catching everything (high recall) or minimizing false alarms (high precision). You can't have both, and pretending otherwise leads to alert configurations that fail at everything.
Here's what those targets look like operationally. Your fleet runs 50 long-haul trucks averaging around 2,800 miles weekly. For critical safety issues—brake system warnings, steering anomalies—you set recall targets at 98%. You'll catch virtually every real problem but investigate plenty of false alarms too. That's acceptable because missing a brake failure could be catastrophic.
For emissions-related codes, flip the priority. Set precision at 85% because these rarely cause immediate breakdowns. You'll miss some legitimate issues temporarily, but your team won't burn time on sensor hiccups that self-resolve. The key is documenting these decisions and reviewing them quarterly based on actual work order outcomes.
Most fleets never take this structured approach. They treat all alerts equally, which guarantees critical warnings get buried in noise while minor issues generate unnecessary work orders.
Building your debounce and aggregation patterns
Raw telematics data is incredibly noisy. A truck hits a pothole, the oil pressure sensor briefly dips, your system fires an alert. The driver turns sharply, lateral acceleration spikes, another alert. Cold morning startup, multiple temperature warnings before everything stabilizes. Without proper filtering, these transient events flood your queue with garbage.
Debouncing means requiring a condition to persist for a minimum duration before triggering an alert. Instead of alerting on every momentary oil pressure drop, you only alert if pressure stays low for more than 15 seconds. This eliminates the vast majority of pothole-induced false positives while still catching real pressure losses quickly enough to prevent damage.
Simple time-based debouncing isn't sophisticated enough for most scenarios, though. You need conditional debouncing that considers context. Oil pressure drops during idle? Probably needs 30 seconds of persistence. Same drop at highway speeds? Alert immediately. Engine temperature spike while climbing a grade in Arizona? Different threshold than the same spike on flat ground in Minnesota.
Pro-tip: Start with conservative debounce windows for idle events and shorter windows for high-speed contexts to avoid missing critical failures.
Aggregation patterns take this further by looking at alert combinations and frequencies. Three different vehicles throwing the same exhaust sensor code within two days? That's worth paying attention to—might be bad fuel or a sensor batch issue. One vehicle throwing multiple unrelated codes simultaneously? Could be an electrical problem affecting multiple systems.
An aggregation pattern that actually works:
Track alert frequency per vehicle over rolling 7-day windows. If a vehicle generates more than 15 alerts in a week, automatically flag it for comprehensive inspection rather than chasing individual issues. This catches deteriorating vehicles that throw cascading faults before they become roadside breakdowns.
Group similar alerts across your fleet. If more than 20% of similar vehicles—same model year, engine type—throw the same code within 48 hours, escalate to engineering review. Catches systematic issues before they spread.
Create alert velocity metrics. A vehicle that goes from zero alerts to five different warnings in one day needs immediate attention. A vehicle that consistently throws one minor alert weekly can wait for scheduled maintenance.
These patterns work with your existing telematics data. No new sensors, no machine learning. Just basic logic that reduces noise while surfacing legitimate patterns.
Context enrichment that eliminates false positives
Your telematics alert for high engine temperature doesn't know that vehicle just climbed a 6% grade for eight miles in 95-degree heat. The hard braking warning doesn't know it happened at a known construction zone. The fuel efficiency alert doesn't realize that truck has been running regional routes instead of highway.
Context enrichment means automatically adding relevant operational data to every alert before it hits your maintenance queue. This transforms noisy sensor data into something your team can actually act on.
Start with route context. Map each alert to the specific route segment where it occurred. That mysterious transmission temperature warning makes more sense when you realize it always happens on the same mountain pass. The recurring speed sensor anomaly correlates perfectly with a specific warehouse's speed bump that drivers hit too fast.
Layer in vehicle state and duty cycle. A cold start warning means something different for a vehicle that's been parked 72 hours versus one that just finished a shift. An emissions fault on a truck running biodiesel blends needs different treatment than the same fault on standard diesel.
Temporal patterns matter too. Alerts that cluster around shift changes might indicate driver behavior rather than mechanical problems. Warnings that only occur during first shift could relate to cold morning starts. Friday afternoon alerts sometimes correlate with rushed pre-weekend operations.
Historical maintenance context changes the picture completely. An oil pressure warning on a vehicle with a recent oil change suggests a different issue than the same warning on a vehicle approaching its service interval. A coolant temperature alert right after radiator service could be an air pocket rather than a real overheat condition.
Environmental data matters more than most fleets realize. Pull in weather data for alert locations. That traction control warning during a rainstorm is less concerning than the same warning on dry pavement. Temperature-related alerts need seasonal adjustment—what's normal in Phoenix would be critical in Portland.
The goal isn't to excuse every alert, but to automatically separate expected variations from genuine anomalies. Your technicians shouldn't waste time investigating engine temperature spikes that are completely normal for the operating conditions.
Your A/B validation loop using work orders
The only way to genuinely improve telematics alert tuning is to systematically compare alerts against confirmed work order outcomes—tracking which alerts led to real repairs versus unnecessary inspections.
Most fleets never close this loop. They generate alerts, create work orders, complete repairs, but never connect the data to ask "was this alert actually predictive of what we found?" Without that validation, you're just guessing about which alerts matter.
Tag every work order with its triggering alert, if any. This seems obvious but requires real discipline. Technicians need to note whether they found an issue related to the alert, found something different, or found nothing at all.
Track alert-to-repair correlation rates monthly. If a specific alert type has less than 40% correlation to actual repairs, it needs retuning. If it's above 80%, you might be missing early warnings by setting thresholds too high.
Create a feedback mechanism for unexpected failures. When a vehicle breaks down without warning, trace back through its alert history. Were there signals you ignored? Patterns you missed? This reverse analysis often reveals which alerts you should be taking more seriously.
Build outcome categories that mean something operationally. Don't just track "true positive" versus "false positive"—that's too simplistic. Track "prevented breakdown," "caught early stage issue," "normal wear identified," "no issue found," and "unrelated issue discovered." These categories help you understand the actual value of different alert types.
For A/B testing new thresholds, split your fleet carefully. Don't randomly assign vehicles. Group by duty cycle, age, and maintenance history to ensure comparable populations. Run tests for at least 60 days to capture enough events for meaningful results.
When you test new alert logic, measure more than accuracy. Track technician hours spent on inspections, breakdown frequency, and total maintenance costs. Sometimes a less accurate alert that's easier to investigate delivers better operational outcomes than a highly accurate one requiring complex diagnosis.
Document your validation results in a simple tracking table:
| Alert Type | Monthly Volume | True Positive Rate | Prevented Breakdowns | Avg Investigation Time | Current Action |
|---|---|---|---|---|---|
| Oil Pressure Low | 47 | 23% | 2 | 35 min | Retune threshold |
| Coolant Temp High | 31 | 67% | 5 | 20 min | Keep current |
| DEF Quality | 89 | 8% | 0 | 15 min | Add context filter |
| Hard Braking | 156 | 71% | N/A | 5 min | Route-based filter |
This systematic validation approach means your alert tuning actually improves over time instead of degrading into noise. The table above gives you a starting template—your numbers will look different, but the categories matter more than the specific figures.
A simple diagram clarifies the loop: alerts map to work orders, technicians tag outcomes, analysts calculate correlation rates, and engineers or operators adjust thresholds in response.
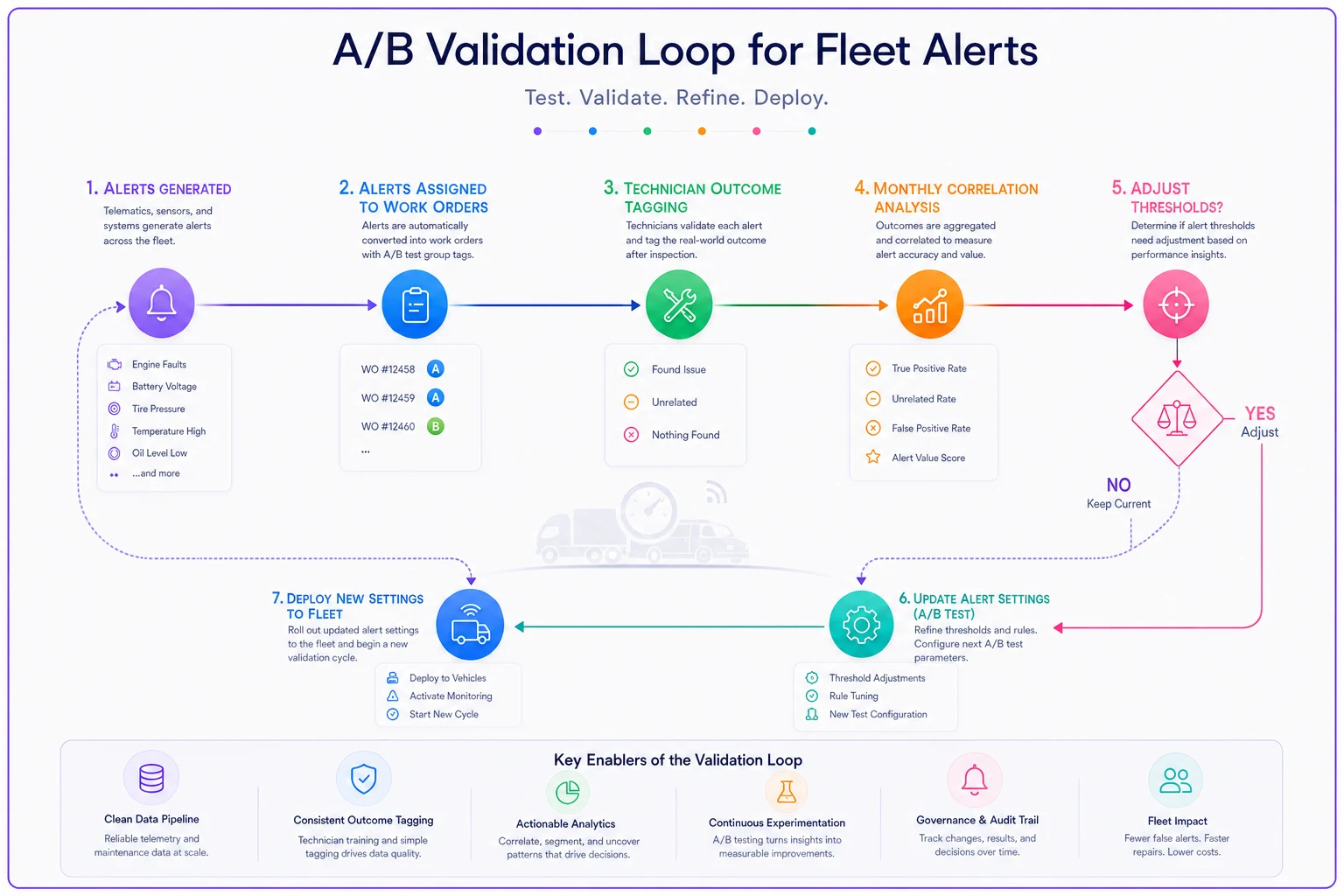
Tagging outcomes and measuring correlation rates monthly closes the feedback loop so tuning becomes data-driven rather than guesswork.
Setting up intelligent alert suppression rules
Not every valid alert needs immediate action. Smart suppression rules prevent alert floods while ensuring critical issues surface when they need to.
End-of-life vehicles scheduled for replacement are a good example. These trucks might throw dozens of alerts weekly as systems degrade, but if they're retiring in 30 days, you only care about safety-critical issues. Create suppression rules that filter everything except brake, steering, and tire warnings for vehicles in their final month.
Suppression during known maintenance windows prevents confusion. When a vehicle enters the shop for scheduled service, suppress non-critical alerts for 48 hours. Your technicians will catch issues during the service anyway, and you avoid duplicate alerts for problems already being addressed.
Geographic suppression rules handle location-specific anomalies. That rough construction site entrance triggers suspension alerts on every vehicle? Suppress those warnings within a defined radius of known problem locations. The alerts still get logged for long-term analysis but don't create immediate work orders.
Cascade suppression prevents alert storms from single root causes. When an alternator fails, it can trigger battery warnings, electrical faults, and various sensor errors. Build logic that recognizes these patterns and suppresses secondary alerts once a primary issue is identified. Keeps your team focused on fixing the actual problem rather than chasing symptoms.
Time-of-day suppression accommodates operational realities. Cold start warnings before 6 AM in winter months might be normal for your northern fleet. Idle alerts during mandated break periods shouldn't generate notifications. These contextual suppressions reduce noise without hiding genuine issues.
Common telematics tuning mistakes that waste money
The biggest mistake is treating telematics alerts like fire alarms—assuming every alert demands immediate response. This creates chaos in your maintenance operation and trains your team to distrust the system.
Another costly error is setting universal thresholds across diverse fleet assets. Your 2019 Freightliners have different normal operating parameters than your 2023 Peterbilts. Your city delivery vans experience different stress than long-haul trucks. Copy-pasting alert configurations across different vehicle types guarantees poor results.
Many fleets fail to account for sensor degradation. As vehicles age, sensor accuracy decreases. That five-year-old temperature sensor might read 3-4 degrees high consistently. Instead of replacing hundreds of aging sensors, build progressive tolerance adjustments based on vehicle age and sensor type.
Over-relying on manufacturer default settings is another expensive habit. OEMs set conservative thresholds to minimize warranty claims, not optimize your operation. Their defaults assume worst-case scenarios and zero context about your specific routes, drivers, and duty cycles.
The "set it and forget it" approach guarantees degrading performance over time. Routes change, vehicles age, driving patterns shift, seasonal variations affect everything. Alert configurations that worked last winter might generate false positive floods this summer. Schedule quarterly reviews to adjust thresholds based on recent validation data.
Ignoring driver-reported issues in favor of telematics data creates dangerous blind spots too. Drivers know when something feels wrong even before sensors detect it. Build processes that weight driver input alongside automated alerts, especially for issues like handling changes or unusual noises that sensors simply can't pick up.
Building your monthly tuning rhythm
Effective telematics alert tuning isn't a one-time project. It's an ongoing operational rhythm that needs to become routine before it delivers real results.
Week 1: Pull your alert accuracy report. Compare last month's alerts against completed work orders. Calculate true positive rates for each alert type. Identify the three worst-performing alerts for deeper analysis.
-
Week 1 Pull your alert accuracy report. Compare last month's alerts against completed work orders. Calculate true positive rates for each alert type. Identify the three worst-performing alerts for deeper analysis.
-
Week 2 Conduct root cause analysis on false positive patterns. Were they caused by environmental factors? Sensor degradation? Route changes? Driver behavior? Understanding why alerts failed helps you adjust intelligently rather than randomly tweaking thresholds.
-
Week 3 Implement threshold adjustments for your worst performers. Document what you changed and why. Set calendar reminders to review these changes in 60 days. Run parallel monitoring on old versus new thresholds when possible.
-
Week 4 Review breakdown incidents that occurred without warning. Check historical data for missed signals. Update alert logic to catch similar issues earlier. Share findings with your technician team so they know what patterns to watch for.
This monthly rhythm maintains momentum without overwhelming your team. You're constantly improving but not constantly changing everything. The documentation builds institutional knowledge so new team members understand why thresholds are set where they are.
Integration with your maintenance workflow
Perfect telematics alert tuning means nothing if alerts don't integrate smoothly with your actual maintenance operations. Too many fleets have beautiful alert dashboards that nobody actually uses because they don't fit the workflow.
Alerts need to route automatically to the right people in the right format. Critical safety alerts should trigger immediate notifications to on-duty supervisors. Maintenance planning alerts can queue for morning review. Driver-actionable alerts should route to drivers first with simple instructions.
Build escalation paths that match your operational reality. If an alert isn't acknowledged within a reasonable timeframe, it should escalate automatically. But "reasonable" varies—a brake warning might need acknowledgment within 30 minutes while an emissions code could wait until the next business day.
Create alert bundling logic for scheduled maintenance. When a vehicle comes due for preventive maintenance, bundle all its minor alerts into the work order. This prevents duplicate shop visits and gives technicians a complete picture of what to investigate.
The handoff from alert to work order needs to preserve context. Don't just create a generic "check engine" work order—include the specific codes, when they occurred, operating conditions, and any patterns identified. This context saves diagnostic time and improves repair accuracy.
Measuring actual improvement
Most fleets track the wrong metrics—total alert volume or alert response time—rather than operational outcomes.
Track breakdown frequency, especially roadside breakdowns that could have been prevented. If your tuning works, this number should drop steadily. Track it by vehicle age category since newer vehicles should have near-zero preventable breakdowns while older vehicles might have acceptable rates.
Measure maintenance cost per mile, not total maintenance spending. As alert accuracy improves, you should catch issues earlier when repairs are cheaper. This metric accounts for fleet growth and utilization changes that affect total costs.
Monitor technician productivity differently. Instead of measuring how many alerts they process, measure how many actual issues they resolve. A technician who investigates 10 alerts and finds 8 real problems is more valuable than one who processes 30 alerts but finds only 5 issues.
Calculate the "alert value ratio"—the total cost of prevented breakdowns divided by total hours spent investigating alerts. This helps you understand the real ROI of your telematics system. Even if you're spending 200 hours monthly on alert investigation, if you're preventing $50K in breakdown costs, that's worthwhile.
Track driver confidence in the maintenance program through simple monthly surveys. When alerts accurately predict problems that get fixed before they affect drivers, confidence builds. When drivers constantly deal with false alarms or missed issues, it erodes quickly.
The path forward
Telematics alert tuning is really about building trust—trust between your maintenance team and the technology, between drivers and the maintenance program, between operations and the entire predictive maintenance strategy. Every false positive erodes this trust. Every missed breakdown destroys it. But every accurately predicted and prevented failure builds it back stronger.
The process outlined here—setting precision/recall targets, implementing debounce patterns, enriching with context, validating against work orders—isn't complex. It just requires discipline and consistency. The fleets that do this well don't have better telematics systems or smarter algorithms. They commit to the monthly rhythm of measurement, adjustment, and validation.
For fleets running operational software that handles maintenance workflows, integrating these tuning practices becomes even more powerful. When alert routing, work order creation, and validation tracking all happen in the same system, the feedback loop tightens automatically. The software can suggest threshold adjustments based on actual repair outcomes, flag alerts that consistently waste time, and surface patterns that are easy to miss when everything lives in spreadsheets.
The bigger mental shift is treating telematics alerts as hypotheses to be validated, not gospel truth. Sensors are good at detecting changes but poor at understanding context. Technicians understand context but can't monitor every vehicle constantly. The combination of smart alert logic and human expertise creates a system that actually prevents breakdowns rather than just documenting them after the fact.
Start with your worst-performing alert type. Apply this framework to just that one alert. Measure results for 60 days. Once you see improvement, expand to the next problematic alert. Within six months, you'll have transformed your telematics system from a noise generator into a predictive maintenance tool your team actually trusts and uses.
The goal isn't perfect prediction—that's not realistic with mechanical systems operating in chaotic real-world conditions. The goal is progressive improvement where each month your alerts become slightly more accurate, your team wastes slightly less time on false positives, and your breakdown rate drops a little more. Those incremental gains compound into real operational advantages over time.
Ready to maximize fleet uptime and reduce maintenance costs?
Join 2,000+ fleet managers using Fleetelyly to streamline maintenance workflows and improve vehicle reliability.

